GraphWrap
New! Version 0.9 of the PDF Extraction Toolkit, which includes GraphWrap, has now been released and is available here.
GraphWrap is a novel approach for user-guided wrapping, or semi-automatic data extraction, from PDF files, which represents the document in an attributed relational graph and performs extraction using an algorithm based on graph matching techniques.
What is wrapping exactly?
Imagine that you have a large amount of data in one or more PDF files, which is presented in a consistent format, such as product specifications, measurements, prices or contact information. In order to make this data amenable to machine processing, it must first be extracted into a structured format such as XML or a relational database. As most PDF files lack the structuring information which would allow us to locate the individual data instances, this is a challenging task.
GraphWrap, which is currently at prototype stage, allows a non-expert user to create such wrappers for almost any PDF file in an intuitive and interactive manner. After selecting an example instance on the document, a few clicks on the graph representation to set conditions and choose which data items to extract are usually all that is required. This wrapper can then be run on other pages and documents which exhibit a similar visual structure. A screenshot of the system is shown below.
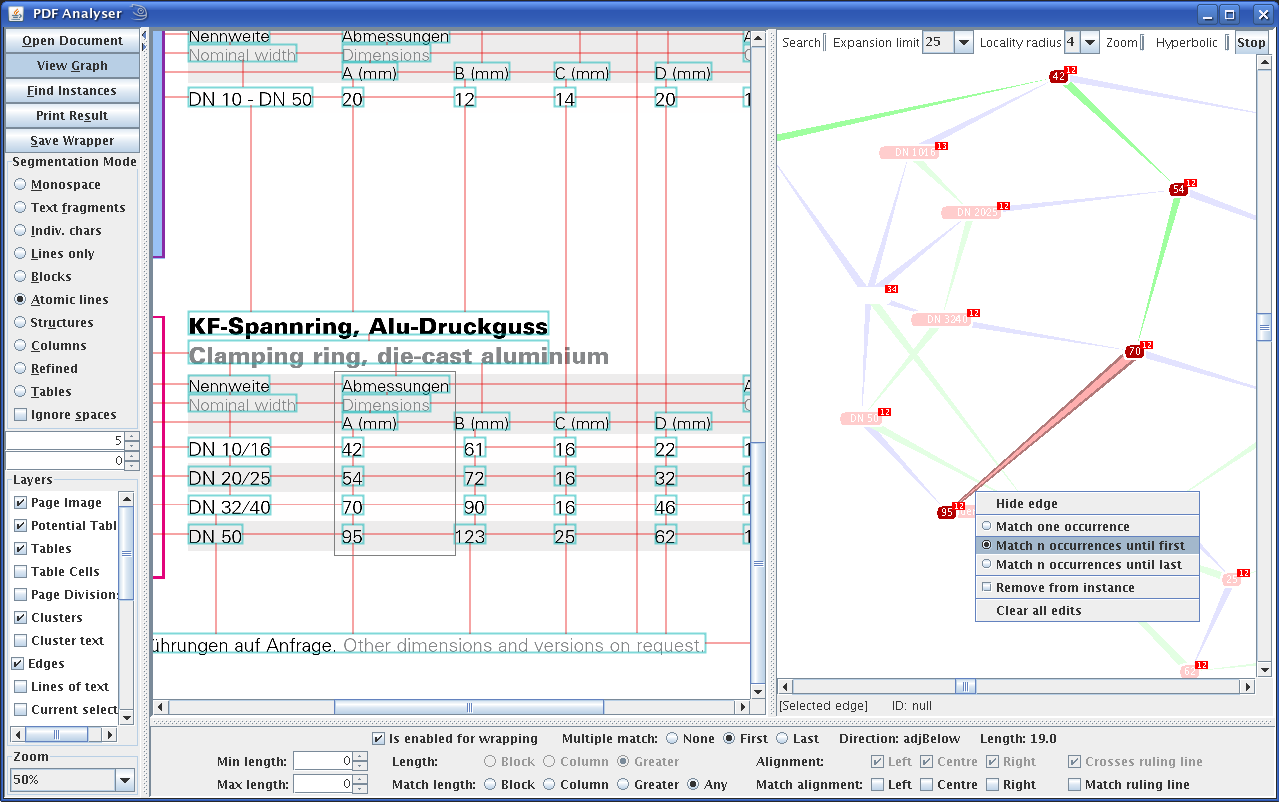
CeBIT presentation
This prototype was presented at CeBIT at the stand of the Austrian Computer Society from 3-5 March 2009. The accompanying handouts from the presentation with instructions for use can be downloaded here in English (PDF) or German (PDF).
Downloadable version
The back-end of GraphWrap is now published under the Apache licence. The GUI, which uses the TouchGraph and XMIllum libraries and can be used to interactively design wrappers, is published under the GPL licence.
Version 0.9 of the PDF Extraction Toolkit, which includes GraphWrap, has now been released and is available here.
Literature on GraphWrap
- Hassan, T.: User-Guided Wrapping of PDF Documents using Graph Matching Techniques (to appear), ICDAR 2009, Barcelona, Spain - This forthcoming paper explains the system in technical detail.
- Hassan, T., Baumgartner, R: Using Graph Matching Techniques to Wrap Data from PDF Documents, WWW 2006 (Poster track), Edinburgh, UK - Before development began, the idea of wrapping using graph matching was presented in this poster.
Instructions
More detailed instructions for the GraphWrap prototype are available in English (PDF) and German (PDF). If you have any further questions, please do not hesitate to send me an e-mail.
back to my homepage