PDF Extraction Toolkit
New! Version 0.9 of the PDF Extraction Toolkit, including GraphWrap, has now been released and is available here.
The PDF Extraction Toolkit (formerly PDF Analyser) is a Java framework built upon the PDFBox library for performing document analysis of PDF files and creating custom conversion methods to HTML and other formats. It is partly based on my PhD work and includes an algorithm for page segmentation. GraphWrap, a system for graph-based wrapping, or semi-automatic data extraction, from PDF files, is also included within the PDF Extraction Toolkit. The main toolkit (including GraphWrap) is released under the Apache licence, which allows it to be freely incorporated into proprietary software.
A GUI is also included, built upon the XMIllum library, which enables the results of the document analysis process to be visualized. Also, an interactive graph visualization is provided to view the graph structures created by the system and allow the interactive creation and testing of graph-based wrappers on PDF documents. This GUI is released under the GPL licence. A screenshot of the GUI in action is shown below.
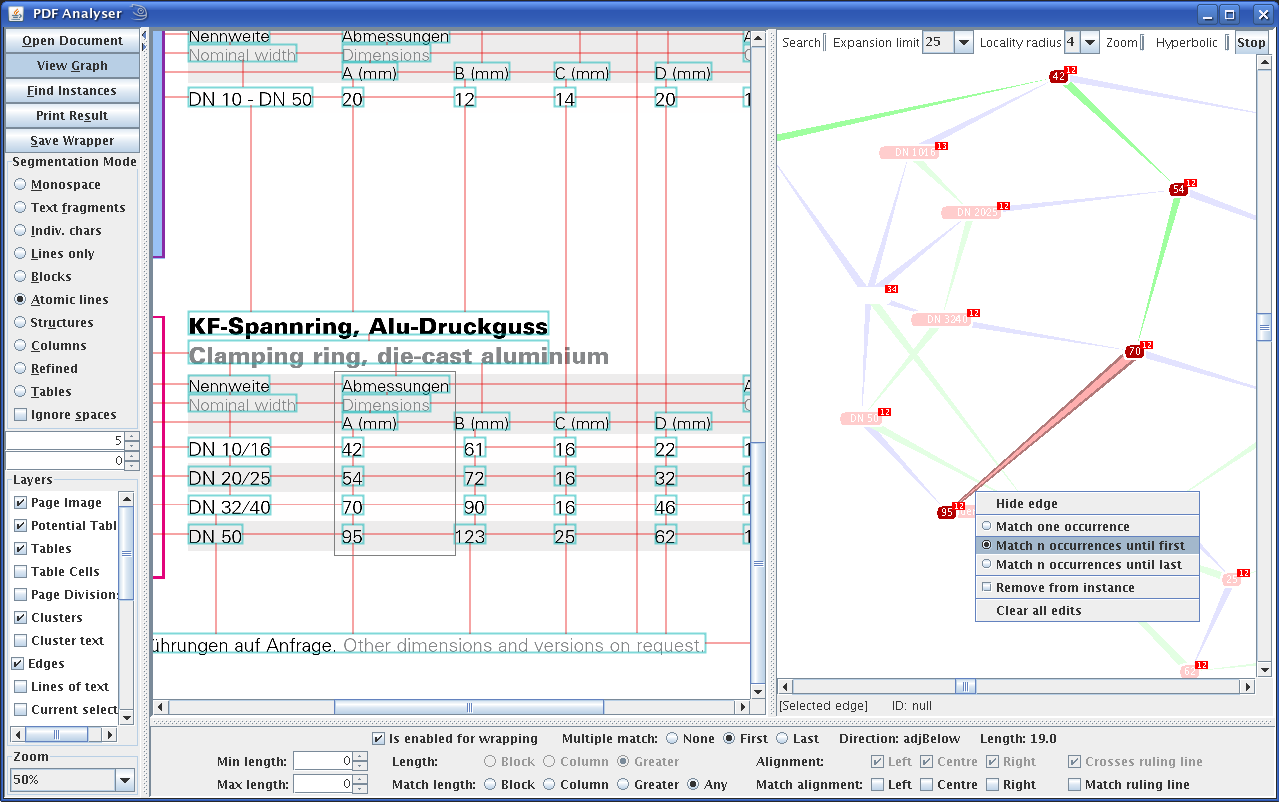
The PDF Extraction Toolkit can be downloaded here. More information on GraphWrap is available here. If you have any further questions, please do not hesitate to send me an e-mail.
back to my homepage