
In this page we can find two different terms for one subject: DynaFLIP++ and CSI(C&F). At this point we would like to remark that DynaFLIP++ stands for all conceptual issues stated in this thesis. CSI(C&F) is a constraint script interpreter on crisp and fuzzy sets, i.e., the implementation of all objectives and functionality of DynaFLIP++. This linguistic distinction may seem not to make a lot of sense, but it is based on a 'historical' motivation. Several different approaches of implementing DynaFLIP++ have been done, and, finally, CSI(C&F) seemed to be the best solution. Earlier implementations adapting the static constraint library ConFLIP++ did not perform as expected, and for this CSI(C&F) was developed.
DynaFLIP++ interacts with FLIP++, the latter being a general purpose fuzzy inference processor library, needed for all computation concerning fuzzification, defuzzification, membership functions, linguistic variables, distributions, etc. DynaFLIP++ wraps additional functionality around these objects and reaches this functionality up to DomFLIP++ where the actual domain knowledge is processed and optimization is performed. This additional functionality has become necessary because of factors encountered in many different real-world optimization problems, of which we only became aware of after trying to handle two different problems, namely steel production scheduling and classroom roostering. Since special consideration is given to the reusability aspect of all libraries, we found that static fuzzy constraints are good to model the aspects associated with partial satisfaction, compromising, and relative importance of constraints. However, other aspects require dynamic generation of constraints from template constraints. For instance, the actual number and kind of constraints often depend upon the current instantiation of the problem that is to be optimized. With each search step in the optimization process, the structure of this instantiation may change. Therefore, the structure of the constraint evaluation tree has also to change. For example, it is possible that a job with an associated delivery date is exchanged with another job that has no delivery date, therefore this constraint must not be evaluated for the second schedule.
Another aspect is that it is normally not useful to tune each constraint separately. Instead, a static constraint is tuned for a selected reference value, and DynaFLIP++ then uses this static constraint to generate a dynamic constraint adapted to the actual situation. Again, looking at the delivery date example, this implies that the template is a static constraint that is tuned around the value zero, with an appropriate fuzzy distribution around it. DynaFLIP++ then specializes this to an actual time in the scheduling horizon, for instance 10 a.m. on April 22, 1996.
This dynamic adaptation is mostly harmless for simple constraints such as delivery dates, but becomes more tricky when complex constraints are involved. A more complex example, also taken from the steelmaking domain, would be the duration of the tundish life expectancy. The problem is that the attributes of a definite number of jobs must be aggregated, in this case by adding their durations, without knowing at the time when the static constraint is defined how many jobs will have to be eventually aggregated. Their number can only be determined dynamically at optimization time by checking certain criteria of the actual schedule instantiation. These aggregation operators are similar to those found in spreadsheet software that process a range of values.
Another difficulty arises because DynaFLIP++ contains absolutely no knowledge about the domain. Using DomFLIP++, optimization structures are defined together with their associated constraints, using the knowledge-engineering features of DynaFLIP++. Additionally, relations between attributes of items in these optimization structures and the static constraints must be defined using a special rule-based language that is interpreted at evaluation time by DynaFLIP++. A rule specifying when and how a template constraint is used. Such a rule, slightly simplified but taken from the actual steelmaking domain, illustrates this mechanism as given in Figure 1:
| CONDITION: |
|---|
| CONSTRAINT: |
Here, "Chemical_compatibility_CC3 <Jobi,Jobi+1>" stands as a macro that links several attribute values of Jobi and Jobi+1 to linguistic variables defined in the pre-tuned static constraints. For the actual implementation, the whole definition of this macro must be specified. The actual compatibility encompasses 12 more chemical alloying elements, the degassing procedure in the secondary metallurgy aggregates, as well as the casting format between the jobs.
To evaluate a given instantiation of a partial constraint satisfaction problem, a decision function aggregating all the constraints with their respective priorities, using an appropriate aggregation operator and a corresponding weighting scheme, must be established. DynaFLIP++ is responsible for efficiently establishing a new global constraint representation for a specific instantiation of the problem. This global constraint will result in a highly structured constraint tree for the whole schedule. The constraint evaluation function will return the weighted global satisfaction score based on the current schedule and the constraint evaluation tree. Figure 2 outlines the general structure of this dynamically constructed tree, where the nodes are weighted aggregation operators (in the simplest case conjunctions) and the leafs are evaluations of individually fine-tuned constraints, again taken from the steelmaking domain. DynaFLIP++ is able to use most of the framework provided by FLIP++ to efficiently compute the evaluation scores for a new schedule.
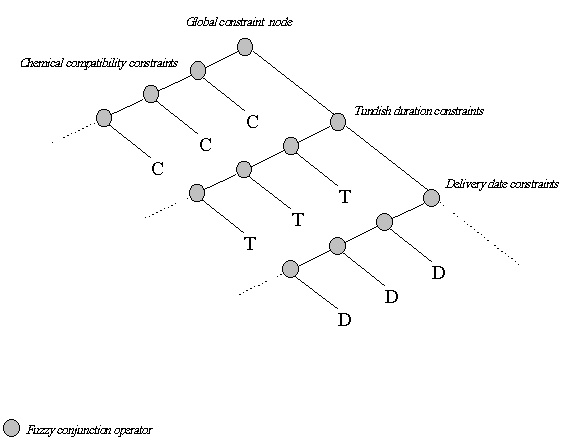
Figure 2: Outline of the constraint tree constructed by DynaFLIP++
When scheduling, it is often advisable to introduce an additional measure into the decision function dependent upon whether the current schedule (= instantiation of the constraint satisfaction problem) contains certain difficult jobs. If the scheduling of these jobs is not introduced as a bonus into the decision function, these jobs might never be considered for actual scheduling. There usually exists a non-empty pool of waiting jobs, and only a subset of jobs from the pool can be scheduled immediately. Therefore, the danger is that some difficult jobs will remain in the pool forever unless additional measures are taken. It is clear that this 'difficulty' or importance of a job must increase over the time for which it is still reasonable to schedule it, to favourize its eventual scheduling.
The easiest way to introduce this 'difficulty'-measure is to formulate a corresponding constraint with an associated priority that will represent these difficult jobs and which will therefore be represented by another branch of a certain constraint type as in Figure 2. Thus, the 'difficulty' of jobs will be one criteria considered when the partial constraint satisfaction problem is optimized. The same applies equally to other partial constraint satisfaction problems such as those encountered in design or planning.
The DynaFLIP++ library is located between FLIP++ and the domain knowledge representation library DomFLIP++, which is a description tool for the environment that has to be optimized. DynaFLIP++ has no restrictions about the complexity of a domain structure, all domain data is imported by the use of CSI(C&F) variables. A description of all CSI(C&F) structures can be found here. In the steelmaking environment a domain holds a list of aggregates, which themselves hold a schedule of objects with their respective attributes and variables. For all variables used within a CSI(C&F)-script one or more constraints can be specified in order to describe relations and restrictions on the process variables. DomFLIP++ is also responsible for repair steps on a badly evaluated schedule, using a list of violations and badly evaluated variables, which are computed at runtime by DynaFLIP++, and the optimization algorithms supported by OptiFLIP++.
To build up the evaluation tree, DynaFLIP++ has to consider the domain structure with its aggregates and scheduling objects, so that the evaluating tree is built up analogous to the hierarchical structure of the modeled application. The structure of the scheduling objects depends on the application they are designed for. Considering production scheduling in industrial environments as a special CSP, we meet different types of imprecision, stemming from constraints that are blurred in definition and include vagueness and uncertainty. We can imagine that an operation on the schedule may start a 'little' earlier and that 'small' deviations of optimal values may be acceptable. The scheduling object 'Order' then has attributes such as plant, plantmark, throughput, weight, format, thickness, speed, slabgroup, chemical_elements, delivery_date, ... and associated constraints like
domain constraint: out_date delivery_dateIn this case, an aggregate could be the continuous caster CC-4, with constraints concerning tundish durations, average throughput, or setup-restrictions. Of course there would exist a variety of other constraints, such as compatibility constraints, capacity constraints, or temporal constraints. To evaluate a schedule for one aggregate, DynaFLIP++ has to first create and instanciate all constraints for the domain objects which are designed by the knowledge engineer. In a second step, all the variables that have restrictions in form of constraints have to be computed. This is done by evaluating the computation clauses designed parallel to the related constraints. The next step is the adaptation of template constraints to the actual situation on the schedule. We can imagine that a template compare value has a fuzzy distribution around zero, but the real compare value may be an aggregation of other processes variables and would have another value.
template constraint: fuzzy_var_foo1 0specialized constraint: out_date - delivery_date 0
On the evaluation of each constraint, DynaFLIP++ invokes the evaluation mechanisms of FLIP++. The evaluated constraints are put into the EVALTREE, where they can be aggregated as described in Figure 2. When all relevant constraints determined by the constraint script interpreter CSI(C&F) are evaluated, the overall evaluation score is returned to DomFLIP++.
Further, we are interested in the biggest violations on the schedule, so we select bad evaluations at runtime and put them into an appropriate data structure, which is later used by DomFLIP++ to make changes on the schedule in order to avoid these violations. The repair steps depend on the optimization algorithm used by DomFLIP++. If a local change on the schedule has occurred, DynaFLIP++ has to check where the changes took place, in order not to build up a complete new evaluation tree, but only to recompute those parts of the schedule that have been changed. This reuse of already computed data structures will, similar to a caching mechanism, influence the runtime behavior of the evaluation process.
The most important object of DynaFLIP++ is the evaluation tree EVALTREE, which contains the specialized and evaluated constraints, and the aggregation of the latter. The variables with their actual values and the violations are stored in a separate structure.
To guide the search of the OptiFLIP++ algorithms as discussed in [Slany94a], it is necessary to identify the constraint with the worst weighted evaluation, i.e., the severest conflict which can be attacked to minimize conflicts. This can be considered as a side product of evaluating the current instantiation. It corresponds to computing the evaluation using the minimum operator, and more importantly, to remember the constraint involved in the minimal weighted evaluation. This constraint represents the largest conflict for the current instantiation. Often the constraint corresponds to a general feature of the instantiation and cannot be attributed to a specific part of the instantiation. Depending on the repair operators available to the repair based constraint satisfaction algorithms, it can be helpful to find additionally the second largest and third largest conflict. Generally, the search should return the largest conflict being of a type that can be handled by an available repair operator. When DynaFLIP++ has to generate a new dynamic constraint representation for a given instantiation, it computes the individual 'leaf' constraints by calling FLIP++ again and again with new variable instantiations on one of the stored reference constraints, and stores the results in an intermediate form that can be used by DynaFLIP++ for further aggregation. This ensures a relatively efficient processing of the constraints since the sometimes very large data structure of a static constraint can be reused for all dynamic constraints of its type. At the same time, DynaFLIP++ sorts all the computed intermediate evaluation scores, together with type information, for later selection of 'good' repair operators. All DynaFLIP++ functionality is implemented by CSI(C&F), an interpreter language for dynamic constraint adaptation and evaluation. In most cases, the values of variables are the result of mathematical or logical expressions, or aggregations of other variables. In this sense CSI(C&F) has to provide a bit more functionality than simple constraint stating and evaluating, thus CSI(C&F) comes quite close to traditional programming languages.
 (c)1996 Andreas RAGGL, Mazen YOUNES, Markus BONNER, Wolfgang SLANY
(c)1996 Andreas RAGGL, Mazen YOUNES, Markus BONNER, Wolfgang SLANY
Last modified: Tue Jun 24 15:39:54 MET-DST 1997
by StarFLIP Team