
DomFLIP++ is one of the central parts of the StarFLIP++ environment. The complete domain knowledge representation is defined in this module. You have also to provide any initial solution for the job to be optimized.
In the following the notions of jobs, aggregates and rules are introduced.
The task at hand is the initial job. This job can of course be sub-divided into ever smaller junks until one reaches a point where further sub-division is no longer possible in a useful manner. The resulting pieces are called atomic jobs. It is these atomic jobs that are to be scheduled later in a meaningful way. Each of these jobs has different properties like the time it takes or its priority for example.
This decomposition of the task should be done with a lot of deliberation. It is as well important to identify as many stand-alone jobs as possible (better as there are) as it is of no good to divide logical steps that belong together into different jobs just because it is possible.
Our initial job is to produce n tons of steel of thickness t and quality q. Some atomic jobs for this task are:
If we could distinguish different steps in the treatment of the chemicals on the assembly line we could of course further sub-divide job 1) though it would be of no use because you cannot change assembly lines in the course of the chemical treatment. In fact this could even prove counter-productive as you would have to introduce some additional rules and constraints later on that would explicitly state that a change of assembly lines is not possible.
An aggregate is an unit (in steel producing usually a machine) on which jobs of the same kind with respect of its use are scheduled. We can again start with a big aggregate that serves us for the whole job and then sub-divide to the extent that we reach smaller aggregates of suitable functionality. These jobs are handled in the same way (e.g. on a paper-cutter) by the aggregate at least for a specific amount of time (though the handling of jobs can also differ if you have as an aggregate a machine that can do different things). It seems clear that there usually will be a rather strong dependence between jobs that are handled on the same aggregate with little time between them. The nearer they are - on the time line - the greater is their dependence i.e. they are treated in a very similar way.
As with jobs you should also take great care while identifying the aggregates. To little leaves you very inflexible while too much could prove counter-productive.
In our steel-making process among other aggregates we could distinguish:
As in the job-example we could easily sub-divide one assembly line into different, smaller aggregates with the same result as above - a system that is more complex without giving more flexibility to optimizations.
After the identification of jobs and aggregates as a next important step we have to define rules. These rules state how jobs (atomic or concatenated ones) or/and aggregates can be interchanged or substituted (if it is not possible to find such rules there is nothing you can optimize). The more rules you can identify the better. Each additional rule adds some more flexibility to your system. An important tag of a rule is how favorable it is to use it.
Correct identification and classification of rules is of utmost importance as they build the foundation for the optimizing cycle.
Some rules for our steel-making example include:
It is important to note that while inadequate dividing of jobs and aggregates could lead to an overly complex or inflexible system that can nevertheless produce results the definition of rules that are wrong will lead to no results in the best case or faulty ones as an alternative.
For any optimizations to take place you have to provide the system with an initial schedule as a starting point for its optimizations. The better the schedule is you provide (with regard to constraint violations) the faster the optimization cycle will be finished though a good initial schedule is not obligatory.
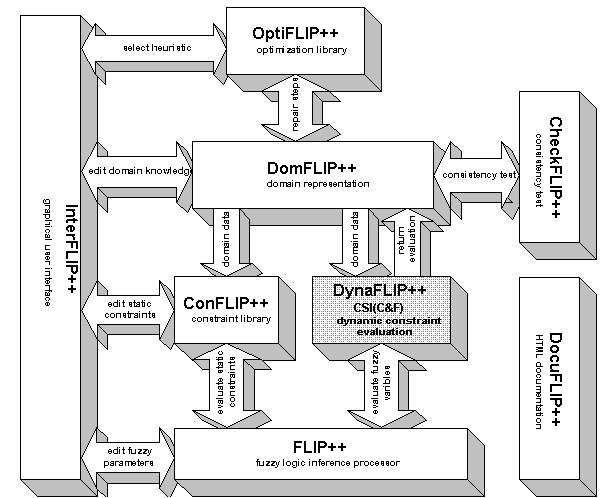
At this time of the development of StarFLIP++ DomFLIP++ is the starting point of the system. From here every other function of the environment is evoked.
Every other unit is either incorporated in DomFLIP++ or called upon from this point (see graphic below).
 (c)1996 Andreas Raggl, Mazen Younes, Markus Bonner, Wolfgang Slany
(c)1996 Andreas Raggl, Mazen Younes, Markus Bonner, Wolfgang Slany
Last modified: Tue Jun 24 15:39:16 MET-DST 1997
by StarFLIP Team